
Der „Matrix Digital Rain“ (auch „Matrix Code“ genannt) ist selbst bei Menschen bekannt geworden, welche die Matrix-Serie nicht im Kino oder auf DVD gesehen haben. Grün leuchtende Zeichen laufen permanent wie Wassertropfen auf einem schwarzen Bildschirm von oben nach unten. Das ganze erinnert optisch an alte Monochrom-Bildschirme der Terminal-Ära. Wenn man daraus nicht für den Commodore C64 einen tollen Screensaver bauen könnte…
In diesem Artikel möchte ich erklären, wie man auf dem C64 japanische Textzeichen verwenden kann. In einem weiteren Artikel werde ich dann erklären, wie man den Matrix Digital Rain erzeugen kann.
Am Anfang steht die Frage, aus welchen Zeichen der Matrix Digital Rain besteht. Der oben zu sehende Snapshot aus dem Film lässt leider auf Grund der Unschärfe nur erahnen, um welche Zeichen es sich handeln könnte. Im Internet gibt es zu dieser Frage einige Aussagen und auch Implementierungen, die sich aber teils widersprechen. Laut Wikipedia:
„This code uses a custom typeface designed by Simon Whiteley, which includes mirror images of half-width kana characters and Western Latin letters and numerals“
Ich selbst konnte auch in Vergrößerungen keine lateinischen Zeichen zweifelsfrei erkennen. Ich bin mir aber recht sicher, unter anderem folgende Zeichen erkannt zu haben:
ハ ニ ソ ム ツ ナ
Dies sind Zeichen einer japanischen Silbenschrift („Kana“), die sich „Katakana“ nennt. Die zweite Silbenschrift nennt sich „Hiragana“, deren Zeichen konnte ich allerdings nicht sicher erkennen. Meine Erklärung dafür: Physische japanische Tastaturen haben neben der Darstellung von lateinischen Zeichen eben diese Katakana-Symbole abgebildet. Viele Leihwörter werden im Japanischen in Katakana geschrieben. Katakana-Symbole lassen sich digital leichter darstellen als Hiragana oder Kanji. Somit waren Katakana-Symbole für Simon Whiteley wahrscheinlich beim Programmieren leichter zugreifbar, auch wenn er laut eigener Aussage sich von Sushi-Rezepten aus dem Kochbuch der Ehefrau inspirieren lassen hat. Ein Kochbuch hätte eher für Hiragana gesprochen.
Sowohl der in Japan eingeführte VIC-1001 (Vorgänger des VIC-20) als auch der Commodore C64 verfügen über eine Tastatur und damit ein digitales Zeichenset („Character Map“ im ROM-Chip) mit Katakana-Symbolen. Auf der Tastatur lassen sich die Katakana-Symbole über Drücken der Commodore-Taste links unten in Kombination mit einer weiteren Taste erreichen.
Auf der Homepage von Bo Zimmerman kann man sich das japanische Character ROM als Binärdatei herunterladen: http://www.zimmers.net/cbmpics/c64js.html. Dieses als Hexdatei dargestellt sieht dann so aus:

Wir betrachten die ersten 8 Bytes 0x00 bis 0x1e. Diese binär dargestellt ergeben ein einzelnes Zeichen aus 8×8 Bits (auf dem Bildschirm 8×8 Pixel):
| 00 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1c | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| 22 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 4a | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| 56 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 |
| 4c | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 |
| 20 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1e | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
Mit etwas Fantasie kann man darin das „@“-Symbol erkennen, welches im japanischen Character ROM als
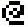
codiert ist. Als nächstes Zeichen mit dem Hex Code 18 24 42 7e 42 42 42 00 folgt das Zeichen „A“ usw. Das Character ROM besteht aus 2 Zeichensätzen á 256 Zeichen, also 256x8x2 Bytes in Summe, einfacher ausgedrückt 4096 Bytes. Das ROM enthält – mal vom Yen-Symbol abgesehen – im ersten Zeichensatz keine japanischen Zeichen. Die sind im zweiten Zeichensatz zu finden:
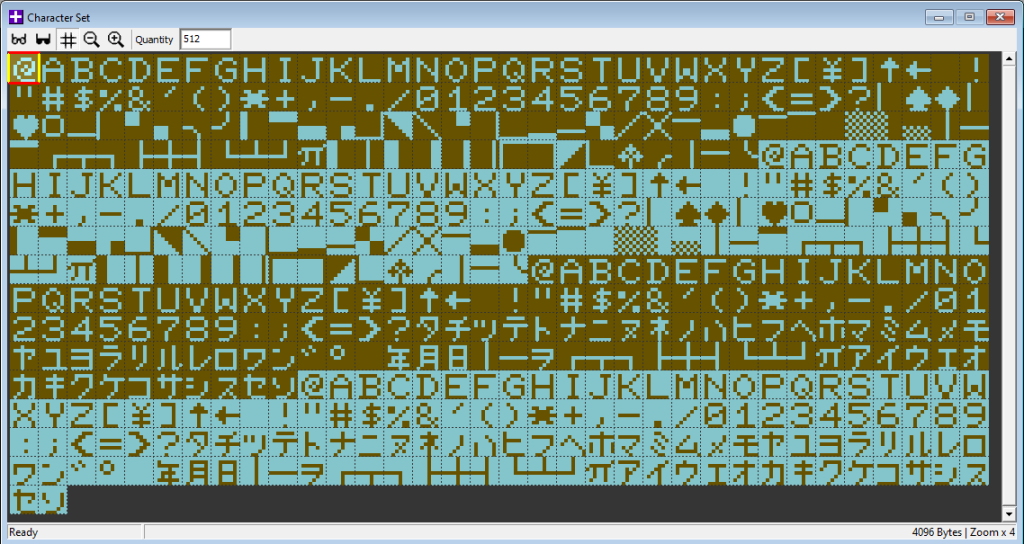
Die jeweils oberen 128 Zeichen des Zeichensatzes enthalten lediglich die invertierten Varianten der Textzeichen.
Da unser Matrix Digital Rain Screensaver in jedem Land, nicht nur in Japan, funktionieren soll, müssen wir das japanische Character ROM in das RAM des Computers einlesen und dort für Software verfügbar machen.
Schritt 1: Dazu benennen wir die Datei des Character ROM „ROM-characters-for-C64-906143-02.bin“ in die kürzere Version „katakana.seq“ um. Mit der Dateiendung .seq geben wir dem Commodore 64 an, dass es sich um eine sequentielle Datei handelt.
Schritt 2: Nun erstellen wir eine neue sequentielle Datei, die lediglich den zweiten Zeichensatz enthält und damit die japanischen Katakana-Symbole. Dazu schreiben wir eine kleine Basic-Routine, die „katakana.seq“ Byte für Byte einließt, den ersten Zeichensatz (2048 Byte) überspringt und dann den zweiten Zeichensatz in die sequentielle Datei „kat.seq“ schreibt:
10 Z$=CHR$(0):REM FOR UNREADABLE CHRS
12 CO=0:REM ADDRESS COUNTER
15 REM OPEN SEQ FILE READ-ONLY
20 OPEN 2,8,0,"KATAKANA,S,R"
25 PRINT "FILE KATAKANA OPENED"
27 REM OPEN SEQ FILE FOR WRITING
30 OPEN 3,8,1,"KAT,S,W"
35 PRINT "FILE KAT OPENED FOR WRITING"
37 PRINT "PLEASE WAIT…"
40 REM READ 1ST CHR MAP
55 REM READ 128X2 BYTES
60 FOR J=0TO255
65 REM READ 8 BYTES FROM FILE
70 FOR I=0TO7
80 GET#2,IN$
82 NEXT I:NEXT J
200 REM READ 2ND CHR MAP
207 REM READ 128X2 BYTES
210 FOR J=0TO255
220 REM READ 8 BYTES FROM FILE
230 FOR I=0TO7
240 GET#2,IN$
250 REM IN HOLDS THE PETSCII CODE OF IN$
260 IN=ASC(IN$+Z$)
270 PRINT IN;
275 REM WRITE CHR TO FILE
280 PRINT#3,CHR$(IN);
290 NEXT I:NEXT J
300 CLOSE 2:CLOSE 3
310 PRINT CHR$(13);"FILES CLOSED"
320 END
Schritt 3: Auf dem Speichermedium befindet sich nun die Datei „kat.seq“, welche die japanischen Zeichen enthält. Jetzt lesen wir diese Datei ein und installieren jedes einzelne Zeichen im Hauptspeicher (RAM) ab Speicheradresse 12288 ($3000):
10 Z$=CHR$(0):REM FOR UNREADABLE CHRS
12 CO=0:REM ADDRESS COUNTER
15 REM OPEN SEQ FILE READ-ONLY
20 OPEN 2,8,0,"KAT,S,R"
25 PRINT "FILE KAT OPENED"
55 REM READ 128 BYTES FROM FILE
60 FOR J=0TO127
65 REM READ 8 BYTES FROM FILE
70 FOR I=0TO7
80 GET#2,IN$
85 REM IN HOLDS THE PETSCII CODE OF IN$
90 IN=ASC(IN$+Z$)
100 PRINT IN;
101 REM MOVING CHRS TO ADDRESS AREA 12288
102 POKE 12288+CO,IN
105 CO=CO+1
110 NEXT I:NEXT J
120 CLOSE 2
130 PRINT CHR$(13);"FILE KAT CLOSED"
140 END
12288 ist in diesem Fall unsere so genannte „Character Dot-Data Area“. An dieser Adresse erwartet der C64 (genauer: der VIC-II Chip) die Textzeichen in einer 8×8 Matrix.
Hinweis: Optimieren könnte man diese Vorgehensweis, wenn man in Schritt 2 lediglich die ersten 128 Bytes in die Datei „kat.seq“ schreibt und damit auf die invertierten Zeichen verzichtet.
Schritt 4: Anschließend wird dem C64 gesagt, dass der neue Zeichensatz statt dem standardmäßigen Zeichensatz im ROM verwendet werden soll:
POKE 53272,(PEEK(53272)AND240)+12
Die Adresse 53272 ($D018) stellt das VIC-II Memory Control Register dar. Die Bits 1 bis 3 geben dem C64 an, wo im Speicher sich die alternativen Zeichentabellen befinden – als Offset zur Startadresse des VIC-II Chips. Standardmäßig befinden sich die Textzeichen der ersten Zeichentabelle ab Adresse 4096 ($1000):
| Bits 3 bis 1 des VIC-II Memory Control Register | Adresse der Character Do-Data Area des VIC-II | Anmerkung |
| 0100 / 4 | $1000 / 4096 | Standard, erste Zeichentabelle inkl. inverse Zeichen, Großbuchstaben plus Grafikzeichen |
| 0110 / 6 | $2000 / 8192 | Zweite Zeichentabelle inkl. inverser Zeichen, Groß- und Kleinbuchstaben |
| 1100 /12 | $3000 / 12288 | Großbuchstaben und Katakana unseres alternativen Zeichensatzes |
Schritt 4: Nun kann man die neuen Zeichen verwenden, in dem man sie zum Beispiel am Bildschirm darstellt:
