Wer heute für die Implementierung eines Risikomanagementsystems der Informationssicherheit zuständig ist, wird wahrscheinlich früher oder später feststellen, dass zwischen der Vielzahl an gesetzlichen und regulatorischen Anforderungen, den normativen Anforderungen und den zugrundeliegenden, mathematischen Methoden ein Lücke klafft:

Die gesetzlichen und regulatorischen Anforderungen auf Ebene 5 sind schnell verstanden. Es wird ein Frühwarnsystem, ein Krisenfrüherkennungssystem, ein Krisenmanagementsystem oder ein System zum Steuern von wesentlichen (bestandsgefährdenden) Risiken gefordert, um Ereignisse, die das Unternehmen in deren Fortbestand gefährden können, rechtzeitig zu erkennen, transparent zu machen und adäquat reagieren zu können. Der dazu notwendige, prozesshafte Umgang mit möglichen (negativen) Zielabweichungen führt unweigerlich zu einem Risikomanagementsystem. Übertragen auf die Informationssicherheit heißt das, dass die mögliche Nichterfüllung der Schutzziele (Vertraulichkeit, Integrität, Verfügbarkeit) als Risiko erkannt und gesteuert werden muss.
Hinweis zur obigen Grafik und der fünften Ebene: Auch wenn die Anwendung innerhalb des Finanz- und Versicherungswesens erfolgt, kann man sich zusätzliche Erläuterungen bei Basel III (inkl. der "Mindestanforderungen an das Risikomanagement", MaRisk) und Solvabilität II abschauen. Weiterhin geben die Prüfungsstandards wie IDW PS 340 Einblick darin, nach welchen Kriterien Wirtschaftsprüfer ein Risikomanagement beurteilen.
Im weiteren Text setze ich voraus, dass ein quantitatives Risikomanagement aufgebaut werden soll. Meiner Meinung nach ist die Integration in die Entscheidungsprozesse des Unternehmens und die Korrelation bzw. Aggregation von Risiken nicht anders zu erreichen.

Nur das quantitative Risikomanagement ist in der Lage, ein Gesamtrisiko zu ermitteln: Während Einzelrisiken an sich nicht bestandsgefährdend sind, kann die Aggregation – also der gleichzeitige Eintritt mehrerer Risiken – durchaus bestandsgefährdend sein! Für ein Unternehmen ist es immer besser, bei bekannten Risiken frühzeitig gegenzusteuern als in die Insolvenz zu gehen und auf staatliche Hilfen zu hoffen.
Normative Anforderungen auf Ebene 4 geben einen risikoorientierten Ansatz innerhalb eines Rahmenwerks („Framework“) vor bzw. ein konkretes Risikomanagementsystem (ISO 27005).
Als Beispiel zeigt ISO/IEC 27005:2018 zwar ein Managementsystem mit Prozess und Tätigkeiten auf, macht aber hinsichtlich der zu verwendenden Methoden keine Aussage. Und dass, obwohl Wikipedia treffend definiert: „Managementsysteme bündeln Tätigkeiten, Instrumente und Methoden der Unternehmensführung“. Offen bleibt also, wie konkret die Risikoanalyse zu gestalten ist.
Ähnlich vage im VDA-ISA-Katalog mit seinen Kontrollen, die in der Automobilindustrie ihre Anwendung finden:
„Ziel eines Informationssicherheits-Risikomanagements ist das frühzeitige Erkennen, Bewerten und Behandeln von Risiken zur Erreichung der Schutzziele der Informationssicherheit. Es befähigt damit die Organisation, unter Abwägung der Chancen und Risiken angemessene Maßnahmen zum Schutz der Informationswerte der Organisation zu etablieren. Es ist empfehlenswert, das Informationssicherheits-Risikomanagement einer Organisation so einfach wie möglich zu gestalten, um es effektiv und effizient betreiben zu können.“
Quelle: VDA-ISA 5.0, Kontrolle 1.4.1
Unklar bleibt, was genau mit „so einfach wie möglich“ gemeint ist und welche Methoden zur Analyse der Risiken in Frage kommen.
Auf Ebene 2 meiner Grafik befinden sich die stochastischen und mathematischen Methoden, welche das oben geforderte, quantitative Risikomanagement möglich machen. Wichtig zum Verständnis sind meines Erachtens die daraus resultierenden Risikomaße: sie lassen sich durch analytische oder Simulationsverfahren bestimmen und helfen dabei, die Risiken verbal zu beschreiben. Damit kann die Brücke geschlagen werden von der Mathematik hin zur Sprache der Entscheider. Testfrage: Wie gut kommt bei Ihnen das Versenden von Dichtefunktionen mit Quantilen an die Geschäftsführung an?
Während die Ebene 4 und 5 noch einigermaßen verständlich ist, kommen viele Menschen mit der Mathematik auf Ebene 2 an ihre Grenzen. Das wichtige „Sonnenscheinmaß“ Value at Risk (VaR) wird zum Beispiel so definiert:

Gut ist, dass uns schlussendlich die zur Analyse und Simulation eingesetzten Risiko-Tools auf Ebene 1 die Mathematik zu einem großen Teil verbergen. Lediglich die Grundprinzipien muss man einmal verstanden haben.
Die Informationssicherheit ist dadurch geprägt, dass typischerweise nur wenige historische Daten zur Verfügung stehen, anders als zum Beispiel bei Zins- und Währungsrisiken. Oftmals sind die öffentlich verfügbaren Informationen über Vorfälle (eingetretene Risiken!) bei anderen Unternehmen hinsichtlich der Schäden vage oder nicht vergleichbar. Dadurch fällt die historische Simulation zur Berechnung von Risiken weg und es bleibt die Risikomodellierung mit anschließender stochastischer Monte Carlo-Simulation. Diese Aussage gilt für viele der operativen Risiken wie Terrorismus-, Reisesicherheit-, Datenschutz- und Compliance-Risiken.
Doch wie werden die Risiken berechnet? Diese Fragestellung auf Ebene 3 bezeichne ich als die Anforderungen an die Risikoanalyse:

Risiken beschreiben, welche Zielabweichungen das Unternehmen treffen könnten. Zur Beantwortung dieser Frage müssen Annahmen getroffen werden, die in einem Risikomodell festgeschrieben werden, welches die Risikofaktoren, Eingangs- und deterministischen Zielgrößen beschreibt. Grundsätzlich soll ein Modell die Realität möglichst gut abbilden und damit Ergebnisse liefern, die wir auch in der Realität erwarten.
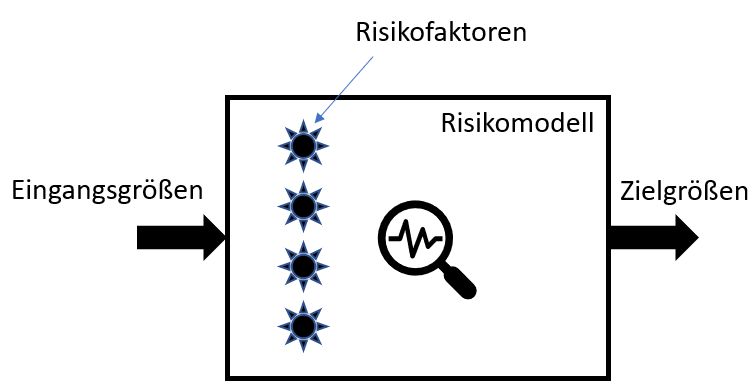
Um ein Risikomodell an einem greifbaren Beispiel zu erklären, nachfolgend das von einem medizinischen Laien (mir) entworfene Modell zur Bestimmung des Schlaganfallrisikos:

Im Modell wurden Risikofaktoren wie der Blutdruck, die HDL/LDL-Cholesterinwerte und das Rauchen als Einflussgrößen definiert. Sobald das Modell fertig ist, wird bildlich der Deckel zugeklappt und es kann nun mit Eingangsgrößen gefüttert werden. Diese sind im Bild links zu sehen. Drückt der Risikomanager auf den Knopf, dann startet die Berechnung des Risikos und es wird nach endlicher Zeit ein Ergebnis ausgegeben.
Verborgen im Modell und der Einfachheit Halber hier weggelassen, sind die Beziehungen zwischen den Risikofaktoren, mögliche Gewichtung und die Regeln zur Berechnung des Schlaganfallrisikos. Zum besseren Verständnis etwas Pseudo-Code, der sich im Modell befinden könnte:
IF Geschlecht = „männlich“ AND Raucher = TRUE
Schlaganfallrisiko = Schlaganfallrisiko x 1,7
IF Geschlecht = „weiblich“ AND Raucher = TRUE
Schlaganfallrisiko = Schlaganfallrisiko x 3
Quelle für diese medizinische Annahme: https://www.pflege.de/krankheiten/schlaganfall/ursachen-vorbeugen/
Wie aber sieht das einfachste Risikomodell in der Informationssicherheit aus? Hier mein Vorschlag für das Risiko „Informationsabfluss“:
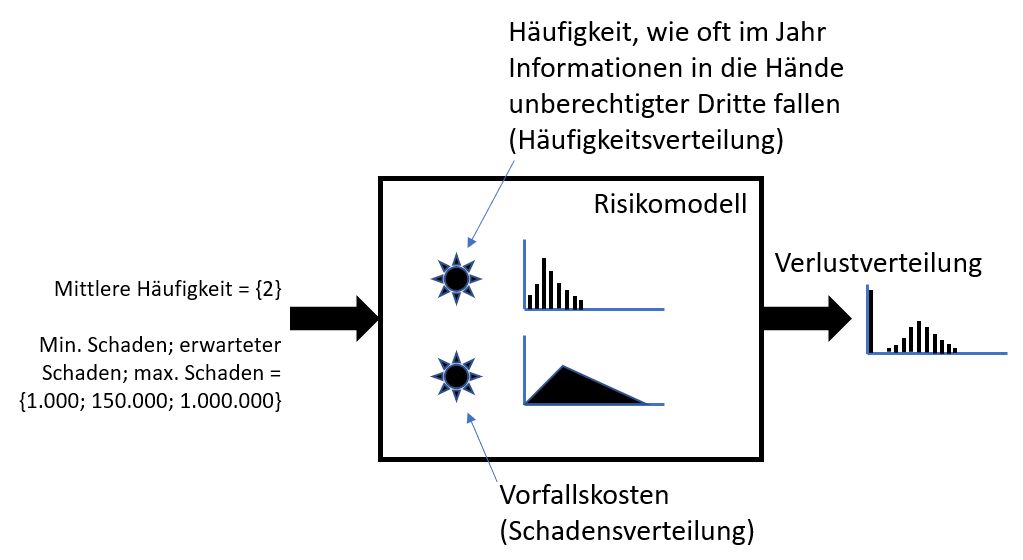
In diesem Beispiel hat ein Experte abgeschätzt, dass im Jahresdurchschnitt mit zwei solcher Vorfälle gerechnet werden muss und dass der Schaden zwischen 1.000 und 1 Mio.€ liegen wird, mit einem erwarteten Schaden von 150.000 €. Das Risikomodell bildet nun aus einer Häufigkeits- und Schadensabschätzung für den Informationsabfluss an unberechtigte Dritte ein Risiko, welches in Form einer Verlustverteilung am Ende der Berechnung als Ergebnis ausgegeben wird. Der Risikomanager kann an Hand der Verlustverteilung nun wichtige Aussagen treffen wie „der mittlere erwartete Schaden ist x Euro“, „ich bin zu 90% sicher, dass der Schaden x Euro nicht übersteigt“ und „in einem von 100 Fällen wir der Schaden x Euro übersteigen“.
Risikofaktoren im oder außerhalb des Modells
Die Frage, von welchem Angreifer wir ausgehen, welche Geschäftsinformationen berücksichtigt wurden, welche Maßnahmen bereits zum Schutz dieser implementiert wurden und wie sich die Vorfallskosten errechnen, ist in dem obigen einfachen Modell nicht implementiert und müsste daher außerhalb dokumentiert werden. Außerhalb heißt in der Praxis meist „nur im Kopf des Risikomanagers“ vorhanden.
Eine in meinen Augen sehr gute und ausführliche Erklärung, wie gerade kleine und mittlere Unternehmen solch einfache Risikomodelle zu einem Unternehmensrisikomanagement zusammenfassen können, findet sich in dem YouTube-Video „Risikoaggregation für PS 340 und StaRUG“. Dort wird bereits auf eine Vor-Maßnahmen- (Brutto) und Nach-Maßnahmen-Betrachtung (Netto) eingegangen.
Der Risikomanager muss sich nun die Frage stellen, ob er auf diesem einfachen Niveau bleiben möchte oder ob das Risikomodell die Risiko-bestimmenden Faktoren enthalten soll. Der große Vorteil der zweiten Variante ist, dass die Herleitung, die zu einer bestimmten Risikoaussage geführt hat, viel besser nachvollzogen werden kann. Im obigen Beispiel möchte man nachvollziehen können, warum gerade die Obergrenze des Schadens 1 Mio. € ist und welche Annahmen zu dieser Aussage geführt haben. Nachvollziehbarkeit schafft Prüfbarkeit schafft Vertrauen!
Aber es gibt auch Nachteile bei diesem Ansatz. Im folgenden Beispiel aus der Informationssicherheit bekommt man ein Gefühl für die mögliche Komplexität von Risikomodellen: Der Erfolg und die Schwere eines Angriffs per Email mit Schadsoftware hängt ab von Faktoren wie
- Welche Unternehmensinformationen sind in Gefahr? Auf welche Informationen mit welchem Wert können die betroffenen Mitarbeiter zugreifen?
- Wer ist der Angreifer? Wie geht dieser vor? Welches Ziel hat er? Wie ist er motiviert?
- Wie oft rechnen wir in einem Zeitraum von zum Beispiel einem Jahr mit einem Angriff? Wie oft rechnen wir mit einem erfolgreichen Angriff?
- In welchem Land bzw. Rechtseinheit geschieht der Angriff? (hat Auswirkungen auf die Vorfallskosten)
- Wie gut sind die Mitarbeiter geschult, solche Emails zu erkennen?
- Wie gut sind die Computer der Mitarbeiter segmentiert und verhindern damit eine Ausbreitung von Schadsoftware?
- Wie gut sind die Computer gegen Privilege Escalation geschützt?
- Wie anfällig ist das Betriebssystem des Computers für Schadsoftware?
- Wie gut funktionieren technische Abwehrmechanismen gegen bösartige Anhänge in Emails?
- Wie gut funktionieren technische Abwehrmechanismen gegen bösartige Links in Emails?
- Wie gut funktionieren technische Abwehrmechanismen gegen Address Spoofing?
- Wie gut funktionieren technische Abwehrmechanismen gegen ähnliche Domain-Namen? (reve.de statt rewe.de)
Die Parametrisierung der Risikofaktoren wird durch bereits umgesetzte und wirksame Schutzmaßnahmen beeinflusst.
Man sieht, dass selbst ein vermeintlich einfaches Risiko „Externer Angreifer greift unerlaubt auf Unternehmensinformationen via Email mit Schadsoftware zu und verursacht einen Schaden“ von vielen Faktoren abhängt, die das Ergebnis (die Schadenserwartung) beeinflussen.
Bottom-Up- versus Top-Down-Modellierung
Ein Aspekt der Risikomodellierung muss noch betrachtet werden: In einem „Bottom-Up-Ansatz“ besteht das Gesamtrisiko zum Beispiel vom Typ „Informationssicherheit“ aus der Aggregation vieler Einzelrisiken, die alle zu diesem Typ gehören. Jedes Einzelrisiko kann unterschiedlich modelliert sein, was die Vergleichbarkeit und Aggregation ernsthaft erschwert.
Anders der „Top-Down-Ansatz“, bei dem für den Typ „Informationssicherheit“ genau ein Risikomodell erstellt wird. Ein Vorteil des „Top-Down-Ansatzes“ drängt sich geradezu auf: die gute Integration in die Unternehmenssteuerung. Das Ergebnis aus der Simulation kann direkt im Controlling abgegeben werden, was bei Hunderten Bottom-Up-Risiken über Schwachstellen in Servern, ungepatchten Systemen und obskuren Applikationen nicht einfach ist. Außerdem können beim „Top-Down-Ansatz“ leichter Szenarien betrachtet werden, die man beim „Bottom-Up-Ansatz“ auf Grund des eingeschränkten Blickwinkels eher außer Acht lässt. Die hohe Komplexität ist wieder einmal der große Nachteil, mit dem man sich beim „Top-Down-Ansatz“ konfrontiert sieht. Das Risikomodell „Informationssicherheit“ lässt sich heute noch nicht aus dem Internet herunterladen und muss daher eigenständig erarbeitet werden.
Achtung! Wählt man das falsche Risikomodell aus, definiert inkorrekte Faktoren oder füttert das Modell mit den falschen Eingangswerten, so entsteht ein neues Risiko, das "Modellrisiko".
Factor Analysis of Information Risk
„Factor Analysis of Information Risk“ (FAIR) könnte eine Antwort auf den Bottom-Up-Ansatz sein. FAIR wird als „the only international standard quantitative model for information security and operational risk“ beschrieben, besteht aber aus einem fixen Risikomodell, macht keinen Unterschied zwischen Eingangsgrößen und Risikofaktoren, kennt pro Faktor nur eine Verteilungsfunktion (beta-PERT) und hat meines Wissens nach in Europa eine geringe Verbreitung gefunden. Dafür ist für das überschaubare Risikomodell „Informationssicherheit“ ein Set an Faktoren mit allen Beziehungen zwischen diesen Faktoren vollständig beschrieben.

Resümee
Nicht viele Risikomanager werden in der Lage sein, zum Beispiel die SAS Model Implementation Platform oder MATLAB zur Risikomodellierung einsetzen zu können. Was aber machen alle anderen? Hier ist meiner Meinung nach ein Vakuum, welches es zu füllen gilt, wenn man irgendwann einmal von einem vollständigen Baukasten des Risikomanagements sprechen möchte.
Excel-basierte Tools wie RiskKit und Oracle Crystal Ball nehmen einem zwar die Simulation ab und stellen das Ergebnis ansprechend grafisch dar, erwarten aber einen fähigen Risikomanager, der Risiken selbstständig modellieren kann. Aus eigener Erfahrung kann ich sagen, dass Modelle mit Faktoren-Abbildung recht komplex und schwer zu warten sein können. Diese Aussage gilt um so mehr, wenn man außerdem Zeitreihen abbilden möchte („Wie hoch wird das Risiko in einem Jahr sein, wenn die Maßnahme x umgesetzt wurde?“).
Meiner Meinung nach sollte auf der Ebene der Risikoanalyse und -modellierung dringend mehr Austausch stattfinden. Zu mindestens innerhalb eines Unternehmens sollten die Risikomodelle gleichen Typs gleich aufgebaut und damit im Ergebnis vergleichbar sein. Gleich aufgebaut heißt hier, dass die Risikofaktoren eines Typs („alle Risiken der Informationssicherheit“) sowie deren Regelsätze einheitlich und fix vorgegeben sind. Ansonsten verschleiert das am Ende der Monte Carlo-Simulation mit Stolz erhaltene Ergebnis lediglich, dass man immer noch Äpfel mit Birnen vergleicht.
Jetzt auch professioneller verpackt: https://www.risknet.de/themen/risknews/luecke-im-bauplan-des-risikomanagements/
Am 17.12.2024 hat mich Luke Bader vom FAIR Institute darüber informiert, dass das “FAIR-U” Tool, welches man oben im Bild sehen kann, Ende Dezember ausläuft und durch zwei neue Risikotools ersetzt werden soll: ein Tabellen-basiertes FAIR-Tool in der ersten Hälfe 2025 sowie „FAIR-U for Cyber“. Über das zweite Tool konnte ich im Internet (https://safe.security/the-fair-standard/) noch nichts finden. Da es aber auf der Safe One-Plattform aufbauen wird, bin ich mal auf die Akzeptanz gespannt.